投稿
コーヒーインク2 #使う
評判がいいアプリゲームをダウンロードしてみた。300円はめちゃくちゃ安い。カフェを経営するアプリで、ものすごく丁寧に作られている。まだ始めたばかりだけど。 経営の僕の癖で気づいたものを書いていこうかなと思う。 まず、別の会社の株を買って設けるのは全く興味ない。 黒字ならOK。 インターネットは高速。コンセント付き。音楽サービス付き。 コーヒー豆はなるべく良いものを。

Volcano PlotでManhattan distance(マンハッタン距離)を計算する方法 #rcommand #bioinformatics
Volcano plotでManhattan distanceを計算するには、以下の手順が必要です。 # 1. データの準備 Volcano plotを作成するために必要なデータは以下の2つです。 - X軸: 各遺伝子の発現量 - Y軸: 各遺伝子のp値 # 2. Manhattan distanceの計算 Manhattan distanceは、2つの点間の距離を、各座標軸の差の絶対値の合計として計算します。 Volcano plotにおけるManhattan distanceは、以下の式で計算できます。 Manhattan distance = |X1 - X2| + |Y1 - Y2| ここで、 - (X1, Y1) は、比較対象となる遺伝子の座標 - (X2, Y2) は、参照となる遺伝子の座標 # 3. Volcano plotへの表示 Manhattan distanceを計算したら、Volcano plot上に表示します。 一般的には、Manhattan distanceが大きい遺伝子を、Volcano plotの右上に表示します。 # 4. 統計分析 Manhattan distanceに基づいて、遺伝子発現とp値の関係を統計分析することができます。 例えば、t検定やWilcoxon signed-rank testを用いて、2つの群間のManhattan distanceの差が統計的に有意かどうかを検定することができます。 # RによるManhattan distanceの計算例 #ライブラリの読み込み library(ggplot2) #データの準備 gene_expression コードは注意してご使用ください。 このコードを実行すると、Manhattan distanceに基づいて作成されたVolcano plotが表示されます。 # 参考資料 - Volcano plot - Wikipedia: https://en.wikipedia.org/wiki/Volcano_plot - Manhattan distance - Wikipedia: https://en.wikipedia.org/wiki/Manhattan_distance
神戸サウナ&スパ #5star #行動する
サ道で紹介されていた神戸サウナ&スパ。神戸三宮駅から徒歩5分程度とかなりの好立地。イメージとしては梅田の大東洋やニュージャパンのようなカプセルホテル&サウナ。しかし、ここは大東洋もニュージャパンも超えた素晴らしいサウナだった。 施設自体が広いのかわからないが、かなりの開放感がある。サウナは大きく3種類。普通のサウナ、フィンランドサウナ(暗くてテレビなし、セルフロウリュ)そして、塩サウナ。大東洋よりも広い感じがするし、何より休憩スペースが充実してて昼寝も余裕でできる。これはリアル桃源郷。近くにあれば毎週でも行きたいけど、遠いからなぁ。でも神戸に来たらまた行きたい。 https://amufaamo.blogspot.com/search?q=%E5%A4%A7%E6%9D%B1%E6%B4%8B https://amufaamo.blogspot.com/search?q=%E3%82%B5%E3%82%A6%E3%83%8A
マックドリトル #3star #食べる
久しぶりに朝マック。朝マックしたのはバイクの教習所に通っている以来かもしれない。 マックドリトルを食べてみるがなんかこれじゃないかもしれない。アマジョッパイ必要ないかな。
みーとがーでん、相変わらず最高だがロースは違いがわからない #食べる
みーとがーでんはいつも混んでいるからなかなか入れないけど、空いているときはたまに入るようにしている。ランチが最高。今日はちょっと高いロースを頼んだけど安い方と違いがよくわからん。これは安い肉も十分美味しいからだと思う。
Rで、データフレームのある列に特定の文字列を含む行のみ取得する方法 #rcommand
Rで、データフレームのある列に特定の文字列を含む行のみ取得するには、いくつかの方法があります。以下で、その方法と、それぞれの特徴について詳しく説明します。 # 方法1:grep関数 grep("文字列", 列名) この方法は、列名に指定された文字列を含む行をすべて抽出します。シンプルな方法ですが、部分一致には対応していないため、注意が必要です。 例: #データフレームの読み込み df # 方法2:grepl関数 grepl("文字列", 列名) この方法は、列名に指定された文字列を含む行をすべて抽出します。grep関数との違いは、部分一致にも対応する点です。 例: #"A"を含む行を抽出 df_filtered # 方法3:str_detect関数 library(stringr) str_detect(列名, "文字列") この方法は、stringrパッケージのstr_detect関数を使用します。grep関数やgrepl関数よりも高速に動作すると言われています。 例: library(stringr) # "A"を含む行を抽出 df_filtered # 方法4:filter関数 library(dplyr) df %>% filter(列名 %in% c("文字列1", "文字列2", ...)) この方法は、dplyrパッケージのfilter関数を使用します。複数の文字列を指定して、それらを含む行を抽出することができます。 例: library(dplyr) #"A"または"B"を含む行を抽出 df_filtered % filter(列名 %in% c("A", "B")) #抽出結果の確認 head(df_filtered) # 方法5:subset関数 subset(df, 列名 == "文字列"...
Rでlistに特定の文字を含むものを排除する方法 #rcommand
Rでlistから特定の文字を含む要素を排除するには、いくつかの方法があります。 # 方法1:grep()関数を使う grep()関数は、文字列ベクトルからパターンに一致する要素を抽出するために使用できます。この場合、パターンは除外したい文字を含む正規表現になります。 list この例では、exclude_charに"c"を指定し、grep()関数で"c"を含まない要素のみを抽出しています。 # 方法2:sapply()関数とgrepl()関数を使う sapply()関数とgrepl()関数を組み合わせて、listの各要素に対してパターンマッチングを行い、除外したい文字を含む要素を削除することもできます。 list この例では、sapply()関数でlistの各要素に対してgrepl()関数を適用し、"c"を含む要素をFALSE、そうでない要素をTRUEとして返しています。 # 方法3:purrr::map_lgl()関数を使う purrrパッケージのmap_lgl()関数を使うと、より簡潔に処理を行うことができます。 library(purrr) list この例では、map_lgl()関数でlistの各要素に対してgrepl()関数を適用し、"c"を含む要素をFALSE、そうでない要素をTRUEとして返しています。 これらの方法のどれを使うかは、コードのスタイルや好みによって選ぶことができます。 # その他の方法 上記以外にも、以下のような方法で特定の文字を含む要素を排除することができます。 - forループを使ってlistの各要素を検査し、除外したい文字を含む要素を削除する。 - filter()関数を使ってlistの要素をフィルタリングする (dplyrパッケージが必要)。 これらの方法は、上記の方法よりも複雑になる場合がありますが、より柔軟な処理を行うことができます。 # 補足 - 上記の例では、除外したい文字を1文字のみ指定していますが、複数の文字を指定することも可能です。 - 大文字と小文字を区別したい場合は、ignore.case = FALSEオプションを指定する必要があります。
R言語で特定の列にNAを含む行を除く方法 #rcommand
R言語で特定の列にNAを含む行を除く方法は以下の通りです。 まず、データフレームが以下のようになっていると仮定します: df 次に、col1列にNAを含む行を除きます: df このコードでは、is.na()関数を使用してcol1列にNAがあるかどうかを確認し、その結果を否定(!)しています。 つまり、col1列にNAがない行だけが選択されます。以上で、特定の列(ここではcol1)にNAを含む行が除かれます。
北大阪急行(御堂筋線)がついに延伸へ。千里中央が終点じゃなくてなってしまった。 #学ぶ
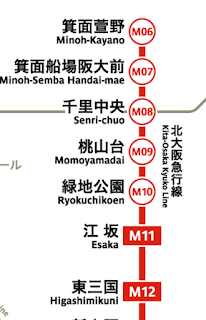
僕の家の最寄り駅の一つである千里中央が終点じゃなくなってしまった。北に2.5 km延伸し、箕面船場阪大前駅と、箕面萱野駅のふたつが新たにできた。 箕面船場阪大前駅周辺、つまりは船場と呼ばれるところは僕の生活圏内で歩いてでも行けるところ。ポパンクールカフェ、マザームーンカフェ、Cafe matinなど、素晴らしいカフェがたくさんあるところ。本当はあまり人は来てほしくないのだけど、これを気に発展してくれることは嬉しいかな。街全体がカフェになって欲しい。 土曜日に歯医者に行くのに、千里中央で電車に乗ったら、たくさん人がいた。特に先頭車両。みんな動画撮りたいんだな。今まで終点だったから、プラットフォームの左右どちらともなかもず行で、どちらかには電車が止まっていたからすぐ座れたけど、今は一方だけが中百舌鳥行になっている。これはちょっと不便。ただし僕の家は北千里も近いので、梅田とか行く場合は北千里から行ったほうがいい。 2024年の3月23日はだいぶ先だと思っていたけど、もう来てしまった。 路線図を見て思ったのだけど、箕面船場阪大前はM7、箕面萱野はM6。ということは将来的にもっと、延伸する予定!?